
AZURE DATA LAKE TUTORIAL FOR BEGINNERS
Azure Data Lake Tutorial includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed. In addition, do all types of processing and analytics across platforms and languages.
What is Azure Data Lake?

First of all, Azure Data Lake works with existing IT investments for identity, management, and security for simplified data management and governance. In other words, it also integrates seamlessly with operational stores and data warehouses so you can extend current data applications. Thus, Microsoft has drawn on the experience of working with enterprise customers and running some of the largest scale processing and analytics in the world for Microsoft businesses like Office 365, Xbox Live, Azure, Windows, Bing, and Skype. Thus, Azure Data Lake solves many of the productivity and scalability challenges that prevent you from maximizing the value of your data assets with a service that’s ready to meet your current and future business needs.
Basically, It removes the complexities of ingesting and storing all of your data while making it faster to get up and running with batch, streaming, and interactive analytics. Hence, Azure Data Lake works with existing IT investments for identity, management, and security for simplified data management and governance. It also integrates seamlessly with operational stores and data warehouses so you can extend current data applications
Build Azure Data Lake solutions using these powerful solutions
HDInsight
Therefore, provision cloud Hadoop, Spark, R Server, HBase, and Storm clusters
Data Lake Analytics
Secondly, distributed analytics service that makes big data easy
Azure Data Lake Storage
Hence, scalable, secure data lake for high-performance analytics
Introduction to Azure Data Lake Storage Gen2 Tutorial
Thus, this tutorial shows how to use Azure Data Lake to do data exploration and binary classification tasks on a sample of the NYC taxi trip and fare dataset. Therefore, the sample shows you how to predict whether or not a tip is paid by a fare. Furthermore, it walks you through the steps of the Team Data Science Process, end-to-end, from data acquisition to model training. After all, it shows you how to deploy a web service that publishes the model.
Prepare data science environment for Azure Data Lake
Furthermore, to prepare the data science environment for this walkthrough, create the following resources:
- Data Lake Storage (ADLS)
- Data Lake Analytics (ADLA)
- Blob storage account
- Machine Learning studio (classic) account
- Azure Data Lake Tools for Visual Studio (Recommended)
The Azure Data Lake Store can be created either separately or when you create the Azure Data Lake Analytics as the default storage. Instructions are referenced for creating each of these resources separately, but the Data Lake storage account need not be created separately.
Azure Data Lake
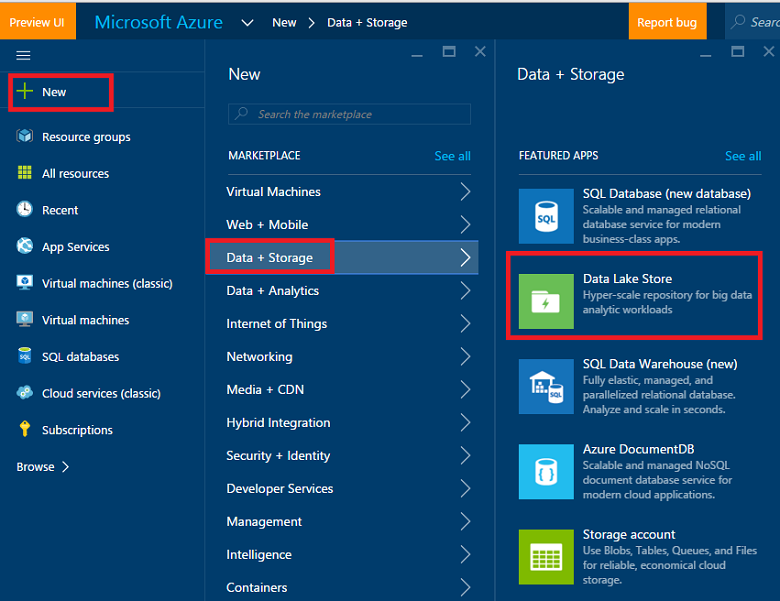
Create an Azure Data Lake Storage
Firstly, create an ADLS from Azure portal. In addition, be sure to set up the Cluster AAD Identity in the DataSource blade of the Optional Configuration blade described there.
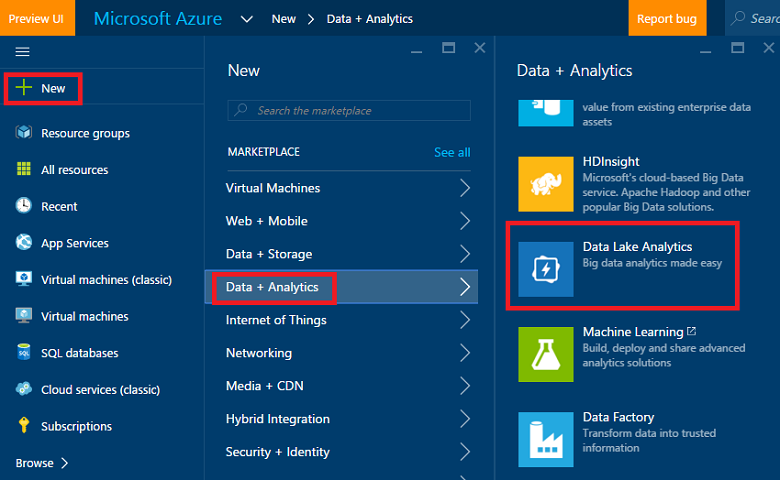
Create an Azure Data Lake Analytics account
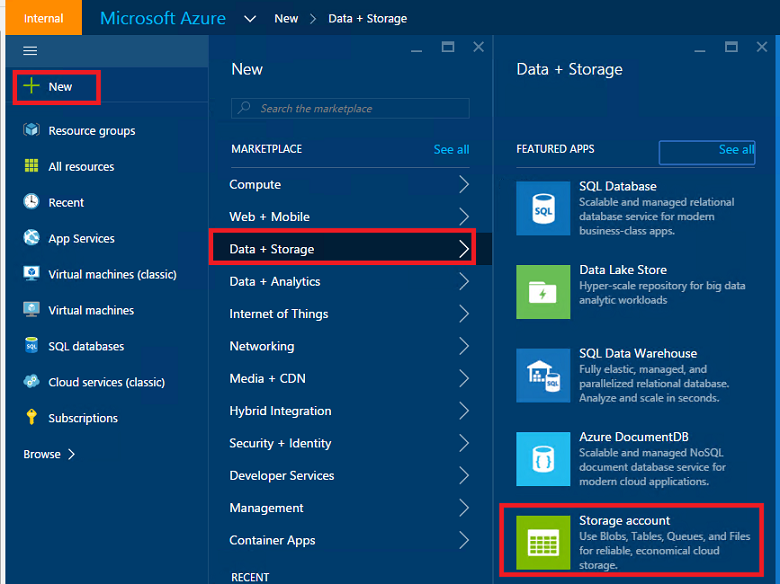
Subsequently, create an Azure Blob storage account
For example, set up an Azure Machine Learning studio (classic) account
Hence, sign up/into Azure Machine Learning studio (classic) from the Azure Machine Learning studio page. Therefore, click on the Get started now button and then choose a “Free Workspace” or “Standard Workspace”. Thus, now your are ready to create experiments in Azure Machine Learning studio.
Install Azure Data Lake Tools
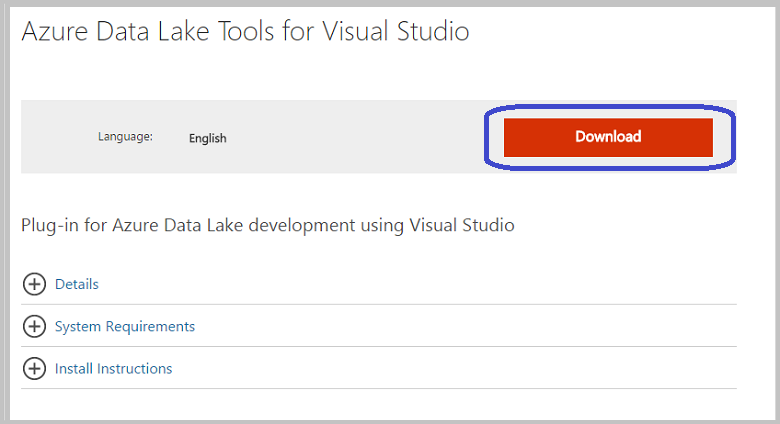

Furthermore, after the installation finishes, open up Visual Studio. Subsequently, you should see the Data Lake tab the menu at the top. Thus, your Azure resources should appear in the left panel when you sign into your Azure account.
The NYC Taxi Trips dataset
After all, the data set used here is a publicly available dataset — the NYC Taxi Trips dataset. Thus, the NYC Taxi Trip data consists of about 20 GB of compressed CSV files (~48 GB uncompressed), recording more than 173 million individual trips and the fares paid for each trip. Above all, each trip record includes the pickup and drop off locations and times, anonymized hack (driver’s) license number, and the medallion (taxi’s unique ID) number.
Process data with U-SQL
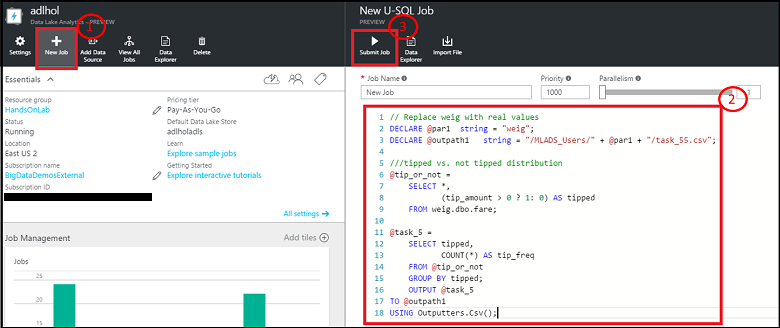
Data Ingestion: Read in data from public blob
Therefore, the location of the data in the Azure blob is referenced as wasb://container_name@blob_storage_account_name.blob.core.windows.net/blob_name and can be extracted using Extractors.Csv(). Substitute your own container name and storage account name in following scripts for container_name@blob_storage_account_name in the wasb address. Since the file names are in same format, it’s possible to use trip_data_{*}.csv to read in all 12 trip files
///Read in Trip data
@trip0 =
EXTRACT
medallion string,
hack_license string,
vendor_id string,
rate_code string,
store_and_fwd_flag string,
pickup_datetime string,
dropoff_datetime string,
passenger_count string,
trip_time_in_secs string,
trip_distance string,
pickup_longitude string,
pickup_latitude string,
dropoff_longitude string,
dropoff_latitude string
// This is reading 12 trip data from blob
FROM “wasb://container_name@blob_storage_account_name.blob.core.windows.net/nyctaxitrip/trip_data_{*}.csv”
USING Extractors.Csv();
// change data types
@trip =
SELECT
medallion,
hack_license,
vendor_id,
rate_code,
store_and_fwd_flag,
DateTime.Parse(pickup_datetime) AS pickup_datetime,
DateTime.Parse(dropoff_datetime) AS dropoff_datetime,
Int32.Parse(passenger_count) AS passenger_count,
Double.Parse(trip_time_in_secs) AS trip_time_in_secs,
Double.Parse(trip_distance) AS trip_distance,
(pickup_longitude==string.Empty ? 0: float.Parse(pickup_longitude)) AS pickup_longitude,
(pickup_latitude==string.Empty ? 0: float.Parse(pickup_latitude)) AS pickup_latitude,
(dropoff_longitude==string.Empty ? 0: float.Parse(dropoff_longitude)) AS dropoff_longitude,
(dropoff_latitude==string.Empty ? 0: float.Parse(dropoff_latitude)) AS dropoff_latitude
FROM @trip0
WHERE medallion != “medallion”;
////output data to ADL
OUTPUT @trip
TO “swebhdfs://data_lake_storage_name.azuredatalakestore.net/nyctaxi_folder/demo_trip.csv”
USING Outputters.Csv();
////Output data to blob
OUTPUT @trip
TO “wasb://container_name@blob_storage_account_name.blob.core.windows.net/demo_trip.csv”
USING Outputters.Csv();
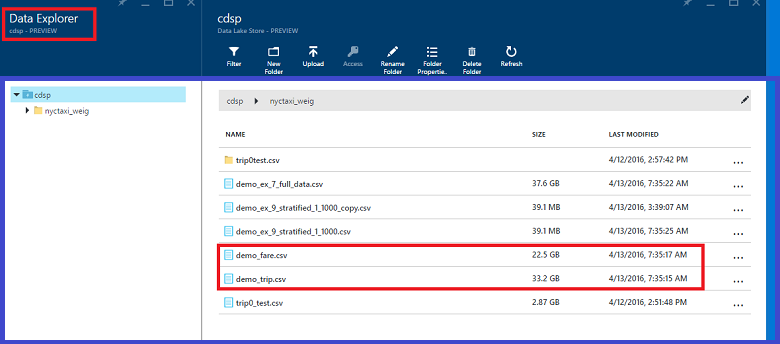
Data quality checks
After trip and fare tables have been read in, data quality checks can be done in the following way. The resulting CSV files can be output to Azure Blob storage or Azure Data Lake Storage.
In addition, now you can build machine learning models based on project requirements.


